Python办公自动化---pdf专栏
日常工作或学习过程中
我们有时需要将1个N页的pdf文件
拆分为每页一个单独的pdf文件
尤其是N数量较大时,我们更需要一电脑种
简便、快速的方法
来完成这项工作
当然,对于多个pdf文件
我们也希望逐个将每个pdf进行如上的拆分
这里我们使用python的PyPDF2库
import PyPDF2
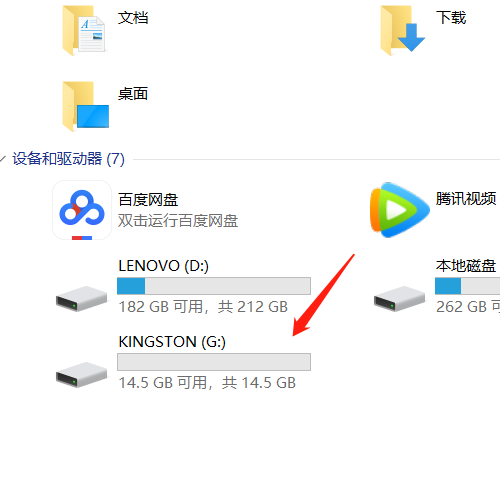
1个7页的605196.pdf文件,保存在E盘下,即e:/605196.pdf,将其拆分7个pdf后,保存在e盘的tmp文件夹下,即e:/tmp/下面。
如上所示:在E盘下有605196.pdf文件和tmp文件夹。
#以下是实现拆分的具体代码
def onePdf_to_nPdf(file, save_path):电脑
with open(file, 'rb') as fr: #读取传入的pdf文件
pr = PyPDF2.PdfFileReader(fr) #将读取的pdf文件转为pdf阅读器对象
num = pr.numPages #获取pdf文件的总页数
print('该PDF文件总页数是:{}页。'.format(num)) #提示pdf的总页数
for i in range(num): #循环一次,即一页pdf
pw = PyPDF2.PdfFileWriter() #实例化1个写入器
pi = pr.getPage(i) #将阅读器对象pr中的第i页读取
pw.addPage(pi) #向写入器写入读取的第i页
name = save_path + str(i+1) + '.pdf' #拼接新pdf的路径和名称,拆分后的每页pdf以其在原文件中的页码,作为新pdf文件的名称
with open(name,'wb') as fw:
pw.write(fw) #将写入器中的内容保存到本地电脑中
if __name__ == '__main__': #主程序的入口
file = 'e:/1.pdf' #需要进行拆分的pdf文件
save_path = "e:/tmp/"
onePdf_to_nPdf(file, save_path) #具体的实现函数
print('完成') #拆分完成后,提示已经完成拆分
解读:在使用以上代码时,将变量file的值修改为pdf所在的完整路径,同时,确定好拆分后的多个pdf保存的文件夹,即save_path,之后将这2个变量,作为参数带入功能函数onePdf_to_nPdf()中。
以上的代码,可以将多页的pdf进行快速拆分,不论这个pdf是几页,还是几百页,都可以很快进行拆分。像几页的、十几页的pdf,1秒或1秒不到,即可完成拆分。几百页,也就几秒拆分完成。
以下是7页的pdf,拆分为7个pdf文件的结果,1秒不到完成拆分。
那么,如果有多个pdf文件,都需要进行拆分,如何处理呢?其实,使用python也很简单。
首先,新增导入import os
然后,修改以下代码:
if __name__ == '__main__': #主程序的入口
path = 'e:/myPdfFiles/' #需要进行拆分的多个pdf文件所在文件夹
files = [path+file for file in os.listdir(path)] #读取所有的pdf文件,保存到列表变量files中
names = [os.path.basename(file).split('.')[0] for file in files] #获取每个pdf的名称,作为该pdf拆分的多个pdf的文件夹名称
os.makedirs('e:/result/') #在E盘新建一个文件夹result,保存拆分后的多个pdf文件夹
for i in range(len(files)):
onePdf_to_nPdf(files[i], names[i]) #具体的实现函数
print('完成') #拆分完成后,提示已经完成拆分
同时,修改onePdf_to_nPdf函数的部分代码:
def onePdf_to_nPdf(file, name):
with open(file, 'rb') as fr: #读取传入的pdf文件
pr = PyPDF2.PdfFileReader(fr) #将读取的pdf文件转为pdf阅读器对象
num = pr.numPages #获取pdf文件的总页数
print('该PDF文件总页数是:{}页。'.format(num)) #提示pdf的总页数
for i in range(num): #循环一次,即一页pdf
pw = PyPDF2.PdfFileWriter() #实例化1个写入器
pi = pr.getPage(i) #将阅读器对象pr中的第i页读取
pw.addPage(pi) #向写入器写入读取的第i页
save_path = 'e:/result/' + name + '/' + str(i+1) + '.pdf' #拼接新pdf的路径和名称,拆分后的每页pdf以其在原文件中的页码,作为新pdf文件的名称
with open(save_path,'wb') as fw:
pw.write(fw) #将写入器中的内容保存到本地电脑中
以上第2部分是将1个pdf进行拆分,第3部分是将多个pdf进行拆分。代码比较简单,但是作用却是很大,能够帮助我们节省很多时间、精力。
更多的python办公自动化案例和经验
请继续关注我们的公众号和头条号
后期会持续进行更新
“白领服务工作室”的系列视频课如下:
Python办公自动化---Python入门课程
Python办公自动化---Python进阶课程
Python办公电脑自动化---正则表达式
Python办公自动化---网络爬虫
Python办公自动化---Excel表格专栏
Python办公自动化---Pdf专栏
Python办公自动化---Word专栏
Python办公自动化---图像专栏
Python办公自动化---数据分析
如需学习以上视频课程,敬请留言!
作者 | 小白
来源 | 原创
编辑 | 白领服务工作室
电脑