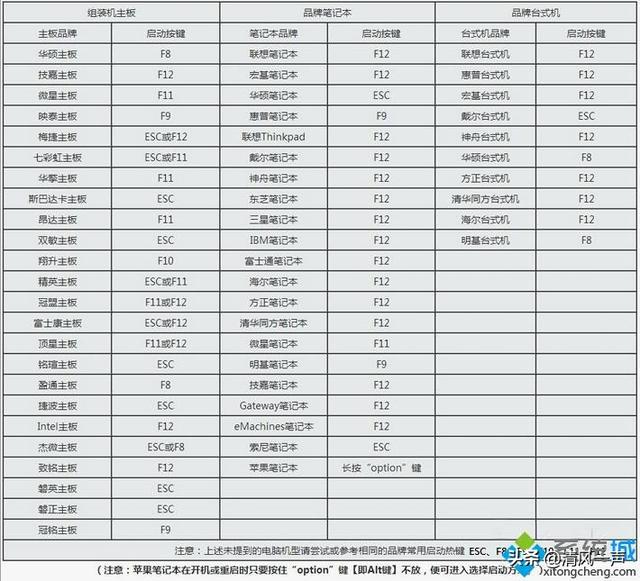
本文研究了一种比目前广为使用的端到端训练模式显存开销更小、更容易并行化的训练方法:将网络拆分成若干段、使用局部监督信号进行训练。
我们指出了这一范式的一大缺陷在于损失网络整体性能,并从信息的角度阐明了,其症结在于局部监督倾向于使网络在浅层损失对深层网络有很大价值的任务相关信息。为有效解决这一问题,我们提出了一种局部监督学习算法:InfoPro。在图像识别和语义分割任务上的实验结果表明,我们的算法可以在不显著增大训练时间的前提下,有效节省显存开销,并提升性能。
01
Introduction (研究动机及简介)
一般而言,深度神经网络以端到端的形式训练。以一个13层的简单卷积神经网络为例,我们会将训练数据输入网络中,逐层前传至最后一层,输出结果,计算损失值(End-to-End Loss),再从损失求得梯度,将之逐层反向传播以更新网络参数。

图1 端到端训练(End-to-End Training)
尽管端到端训练在大量任务中都稳定地表现出了良好的效果,但其效率至少在以下两方面仍然有待提升。其一,端到端训练需要在网络前传时将每一层的输出进行存储,并在逐层反传梯度时使用这些值,这造成了极大的显存开销,如下图所示。
图2 端到端训练具有较大的的显存开销
其二,对整个网络进行前传-->反传的这一范式是一个固有的线性过程。前传时深层网络必须等待浅层网络的计算完成后才能开始自身的前传过程;同理,反传时浅层网络需要等待来自深层网络的梯度信号才能进行自身的运算。这两点线性的限制使得端到端训练很难进行并行化以进一步的提升效率。

图3 端到端训练难以并行化
为了解决或缓解上述两点低效的问题,一个可能的方案是使用局部监督学习,即将网络拆分为若干个局部模块(local module),并在每个模块的末端添加一个局部损失,利用这些局部损失产生监督信号分别训练各个局部模块,注意不同模块间没有梯度上的联通。下图给出了一个将网络拆分为两段的例子。

图4 局部监督学习(Locally Supervised Learning)
相较于端到端训练的两点不足,局部监督学习在效率上先天具有显著优势。其一,我们一次只需保存一个局部模块内的中间层输出值,待此模块完成反向传播后,即可释放存储空间,进而复用同样的空间用以存储下一个局部模块的中间层输出值,如下图所示。简言之,理论上显存开销随局部模块数呈指数级下降。

图5 局部监督学习可有效降低显存开销
其二,不同局部模块的反向传播过程并没有必然的前后依赖关系,在工程实现上,不同模块的训练可以自然的并行完成,例如分别使用不同的GPU,如下图所示。
图6 局部监督学习易于并行化完成
02
Analysis (问题分析与假设)
相信大家看到这里,都会有一个问题:既然局部监督学习的效率自然地高于端到端训练,为什么它现在没有被大规模应用呢?其问题在于,局部监督学习往往会损害网络的整体性能。
以图片识别为例,考虑一种简单自然的情况,我们使用标准的线性分类器+SoftMax+交叉熵作为每个局部模块的损失函数,在CIFAR-10数据集上使用局部监督学习训练ResNet-32,结果如下所示,其中代表局部模块的数目。可以看出随着值的增长,网络的测试误差急剧上升。
图7 局部监督学习倾向于损害网络性能
若能解决性能下降的问题,局部监督学习就有可能作为一种更为高效的训练范式而取代端到端训练。出于这一点,我们探究和分析了这一问题的原因。
上述局部监督学习和端到端训练的一个显著的不同点在于,前者对网络的中间层特征直接加入了与任务直接相关的监督信号,从这一点出发,一个自然的疑问是,由此引发的中间层特征在任务相关行为上的区别是怎样的呢?因此,我们固定了图7中得到的模型,使用网络每层的特征训练了一个线性分类器,其测试误差如下图右侧所示。其中,横轴代码取用特征的网络层数,纵轴代表测试误差,不同的曲线对应于不同的k取值,k=1 表示端到端的情形。

图8 中间层特征的线性可分性
从结果中可以观察到一个明显的现象:局部监督学习所得到的中间层特征在浅层时就体现出了极好的线性可分性,但当特征进一步经过更深的网络层时,其线性可分性却没有得到进一步的增长;相比而言,尽管在浅层时几乎线性不可分,端到端训练得到的中间层特征随着层数的加深可分性逐渐增强,最终取得了更低的测试误差。于是便产生了一个非常有趣的问题:局部监督学习中,深层网络使用了分辨性远远强于端到端训练的特征,为何它得到的最终效果却逊于端到端训练?难道基于可分性已经很强的特征,训练网络以进一步提升其线性可分性,不应该得到更好的最终结果吗?这似乎与一些之前的观察(例如deeply supervised net)矛盾。
为了解答这个疑问,我们进一步从信息的角度探究网络特征在可分性之外的区别。我们分别估计了中间层特征h与输入数据x和任务标签y之间的互信息 I(h,x)和 I(h,y),并以此作为h中包含的全部信息和任务相关信息的度量指标。

图9 估算互信息
其结果如下图所示,其中横轴为取用信息的层数,纵轴表示估计值。从中不难看出,端到端训练的网络中,特征所包含的总信息量逐层减少,但任务相关信息维持不变,说明网络逐层剔除了与任务无关的信息。与之形成鲜明对比的是,局部监督学习得到的网络在浅层就丢失了大量的任务相关信息,特征所包含的总信息量也急剧下降。我们猜测,这一现象的原因在于,仅凭浅层网络难以如全部网络一般有效分离和利用所有任务相关信息,因此索性去丢弃部分无法利用的信息换取局部训练损失的降低。而在这种情况下,网络深层接收到的特征相较网络原始输入本就缺少关键信息,自然难以基于其建立更有效的表征,也就难以取得更好的最终性能。

图10 中间层特征包含的信息
基于上述观察,我们可以总结得到:局部监督学习之所以会损害网络的整体性能,是因为其倾向于使网络在浅层丢失与任务相关的信息,从而使得深层网络空有更多的参数和更大的容量,却因输入特征先天不足而无用武之地。
03
电脑Method (方法详述)
为了解决损失信息的问题,本文提出了一种专为局部监督学习定制的损失函数:InfoPro。首先,我们引入一个基本模型。如下图所示,我们假设训练数据受到两个随机变量影响,其一是任务标签y,决定我们所关心的主体内容;其二是无关变量r,用于决定数据中与任务无关的部分,例如背景、视角、天气等。

图11 变量作用关系假设
基于上述变量设置,我们将InfoPro损失函数定义为下面的结合形式。它用于作为局部监督信号训练局部模块,由两项组成。第一项用于推动局部模块向前传递所有信息;在第二项中,我们使用一个满足特殊条件无关变量r*来建模中间层特征中的全部任务无关信息(无用信息),在此基础上迫使局部模块剔除这些与任务无关的信息。

图12 InfoPro损失函数
InfoPro与端到端训练和在 2. Analysis 中所述的简单局部监督学习(Greedy 电脑Supervised Learning)的对比如下图所示。简言之,InfoPro的目标是使得局部模块能够在保证向前传递全部有价值信息的条件下,尽可能丢弃特征中的无用信息,以解决局部监督学习在浅层丢失任务相关信息、影响网络最终性能的问题。事实上,这也是我们前面观察到的、端到端训练对网络浅层的影响形式。InfoPro与其它局部学习方法最大的区别在于它是非贪婪的,并不直接对局部的任务相关行为(如Greedy Supervised Learning中基于局部特征的分类损失)做出直接约束。
图13 3种训练算法的对比
在具体实现上,由于InfoPro损失的第二项比较难以估算,我们推导出了其的一个易于计算的上界,如下图所示:

图14 InfoPro损失的一个易于计算的上界
关于这一上界的具体推导过程、一些数学性质和其实际上的计算方式,由于流程比较复杂且不关键,不在此赘述,欢迎感兴趣的读者参阅我们的文章~
04
Experiments (实验结果)电脑
在不同局部模块数目的条件下,稳定胜过baseline

大量节省显存,且不引入显著的额外计算/时间开销,效果相较端到端训练略有提升

ImageNet大规模图像识别任务上的结果,节省显存的效果同样显著,效果略有提升

Cityscapes语义分割实验结果,除节省显存方面的作用外,我们还证明了,在相同的显存限制下,InfoPro可以使用更大的batch size或更大分辨率的输入图片

05
Conclusion (结语)
总结来说,这项工作的要点在于:
(1)从效率的角度反思端到端训练范式;
(2)指出了局部监督学习相较于端到端的缺陷在于损失网络性能,并从信息的角度分析了其原因;
(3)在理论上提出了初步解决方案,并探讨了具体实现方法。
电脑 电脑