最近看到一篇文章介绍了利用Python爬虫爬取B站视频封面的文章,虽然我完全没看文章,但是只看了一眼这个封面图就彻底把我吸引了。不过我也对爬虫这方面比较熟悉了,这么简单的事情还用看别人的文章教我做事?当然是自己动手丰衣足食啦!
(此处请自行想象.JPG)
确定思路
首先自然是先用F12开发者工具看看这个页面的样子了。这一步简直顺利的无懈可击,一下子就找到了封面图的地址,就是下图红框所示的地址。在浏览器中打开看看,果然正是这个封面图。但是话又说回来,这个封面图是不是小了点?这就要说到图片CDN的一个功能了,如果大家有用过这类服务的话,一般这种图片服务都支持按照尺寸加载图片,也就是这个地址最后的320w_240h。如果是这样的话,那么我们把它改成大尺寸的1920*1080,不就是可以得到高清大图了吗?这么一尝试果然如此,好了,那么问题就解决了。
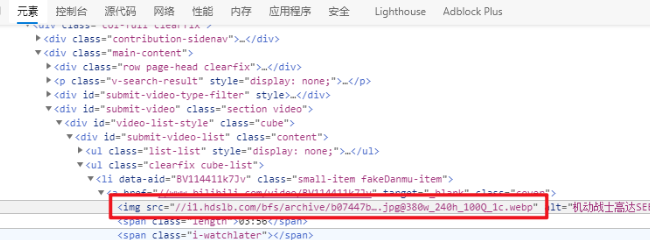
封面图地址
解决异步加载
但是实际操作的时候,又遇到了一个问题。那就是代码完全正确,但是结果却一个网页元素都获取不到了。这可让我百思不得其解,百般尝试之后无奈再回头看看人家的文章是怎么说的。原来B站的网页是异步加载的,如果用爬虫直接获取的话,只会得到如下图所示的空空如也的页面,实际的网页内容都是通过JavaScript执行以后获得的。比较遗憾的是,我尝试用requests-html的render函数渲染浏览器实际页面,也没有成功。

没有实际内容的网页内容
这时候就要说回到异步加载了,既然这些信息是异步加载出来的,那么我们看看能否从网页中找到一些线索。实际上还真有这么一个东西,就是下图中search这个请求,它请求的地址是api开头的网址,一般都是干返回JSON数据的。如果不好找的话,可以从红框那里选择筛选类别来进行更详细的查找。总之,这个请求就是我们要找的东西,它返回的正是当前页面的封面图JSON数据,最关键的是,它这里的图片直接就是1920*1080高清大图,直接省了不少事情。而且这个请求的参数直接就包含了页数,所以我们只要取到总页数,用这个api拉图片地址就完事了。
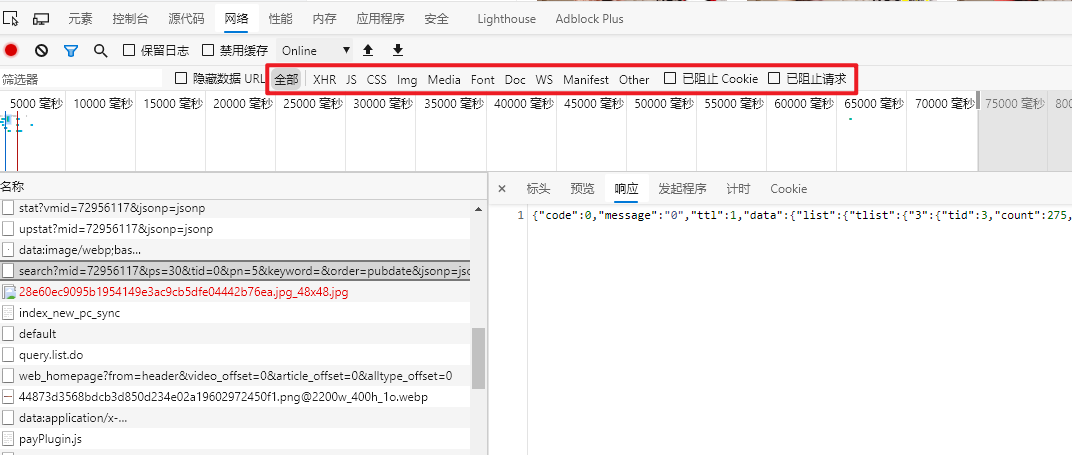
寻找加载方式
实际代码和效果
好了,下面就是最终的代码了。代码按照函数来组织,应该非常容易理解,因为我这里使用视频封面图的标题来当做文件名,所以可能会出现不能当做文件名的非法字符。因此我还加了一个函数专门来去除非法字符。默认图片保存路径是桌面,可以更改到其他位置。
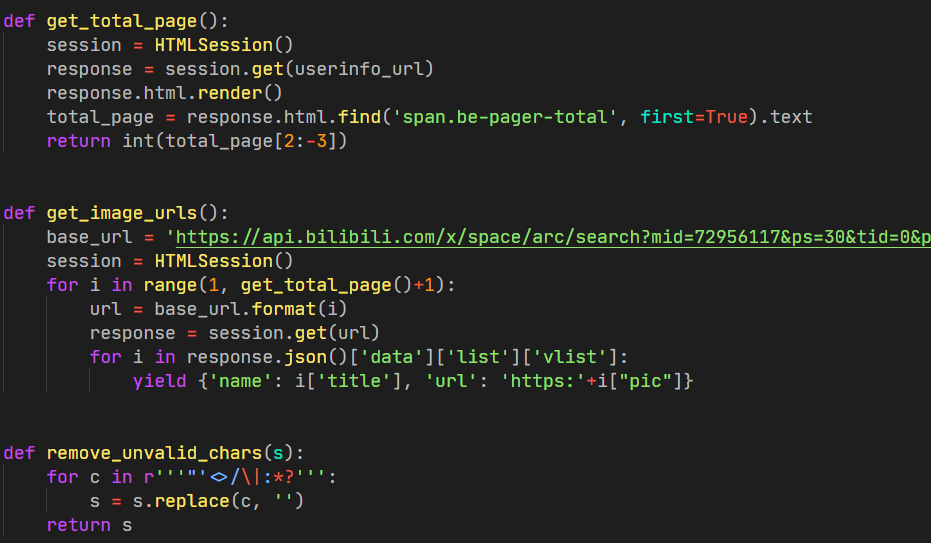
部分代码截图
from requests_html import HTMLSession
userinfo_url = 'https://space.bilibili.com/72956117/video'
save_folder = r'~/Desktop/images'
def get_total_page():
session = HTMLSession()
response = session.get(userinfo_url)
response.html.render()
total_page = response.html.find('span.be-pager-total', first=True).text
return int(total_page[2:-3])
def get_image_urls():
base_url = 'https://api.bilibili.com/x/space/arc/search?mid=72956117&ps=30&tid=0&pn={0}&keyword=&order=pubdate&jsonp=jsonp'
session = HTMLSession()
for i in range(1, get_total_page() 1):
url = base_url.format(i)
response = session.get(url)
for i in response.json()['data']['list']['vlist']:
yield {'name': i['title'], 'url': 'https:' i["pic"]}
def remove_unvalid_chars(s):
for c in r'''"'<>/\|:*?''':
s = s.replace(c, '')
return s
def download_images():
import pathlib
import requests
import shutil
folder = pathlib.Path(save_folder).expanduser()
if not folder.exists():
folder.mkdir()
for i in get_image_urls():
response = requests.get(i['url'], stream=True)
filename = remove_unvalid_chars(i["name"]) '.jpg'
with open(folder/filename, 'wb') as f:
shutil.copyfileobj(response.raw, f)
print(f'{i["name"]}.jpg下载完成')
download_images()
运行完毕之后就可以得到满满一个文件夹的图片了,然后就可以一个人找个闲暇时间静静的欣赏了。

此处请继续自行想象