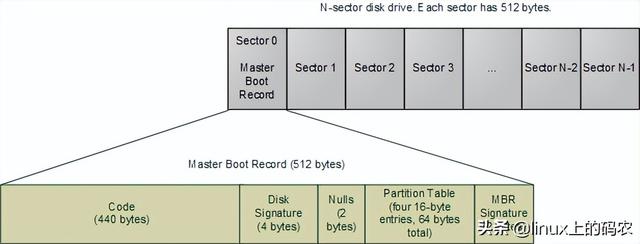
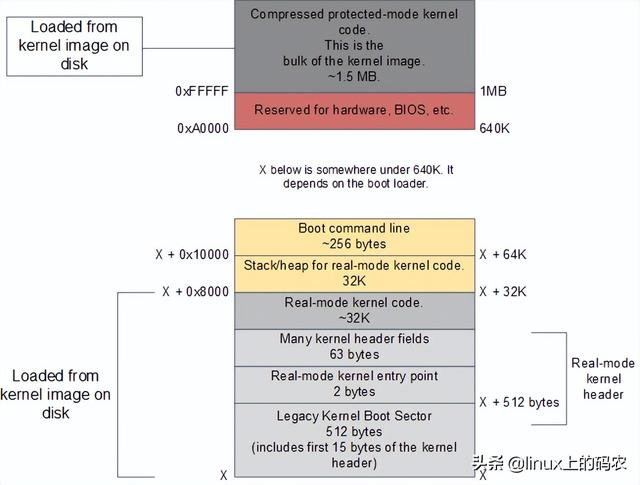
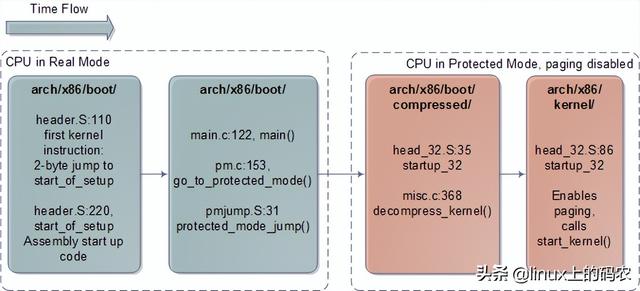
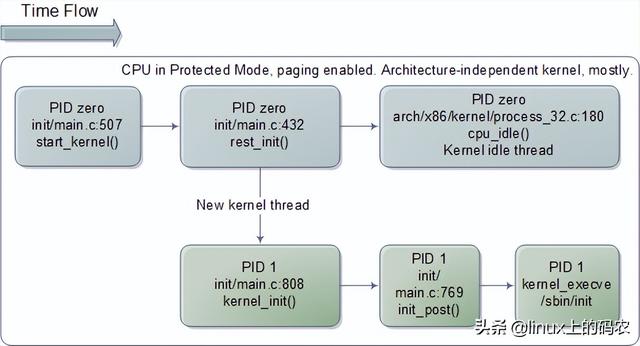
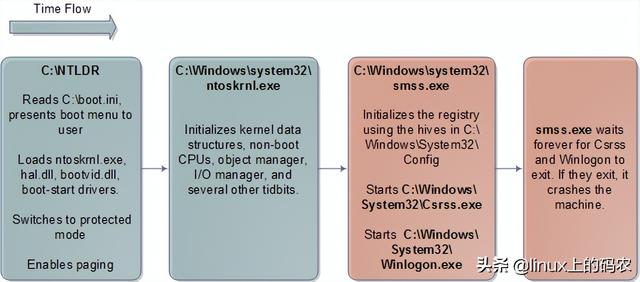
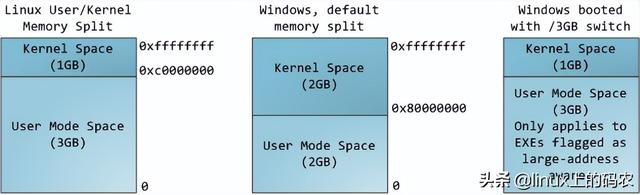
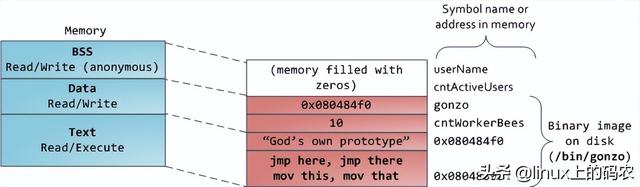
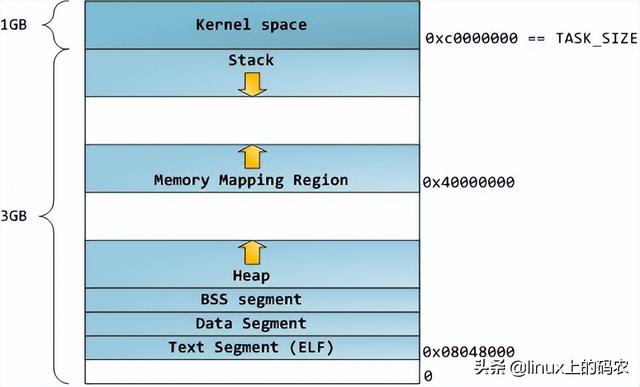
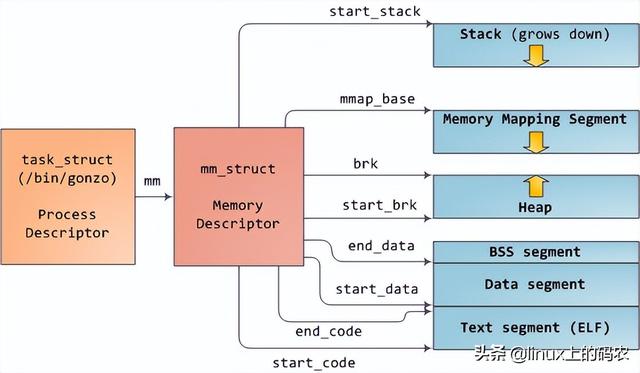
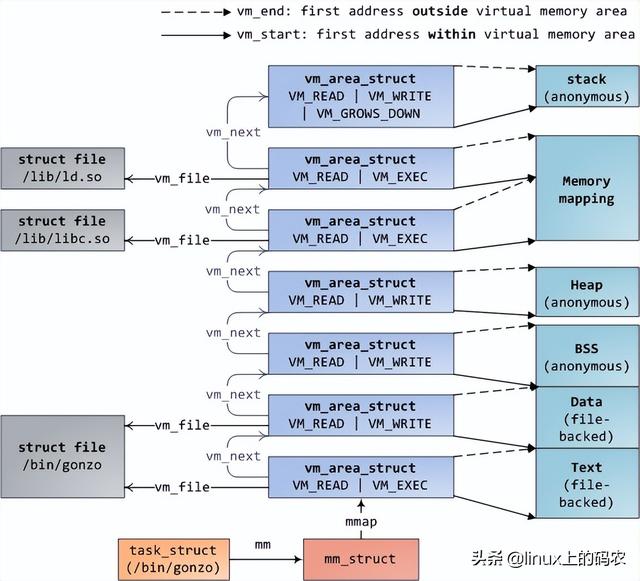
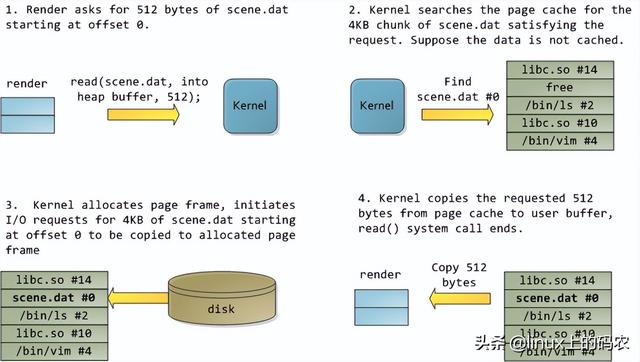
计算机系统出现booting
(计算机系统出现bootmanager)
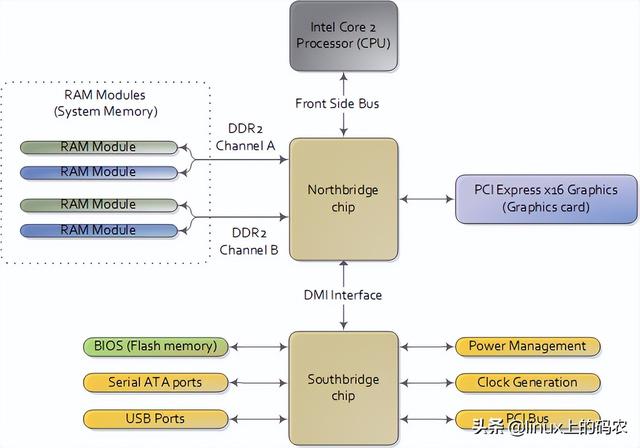
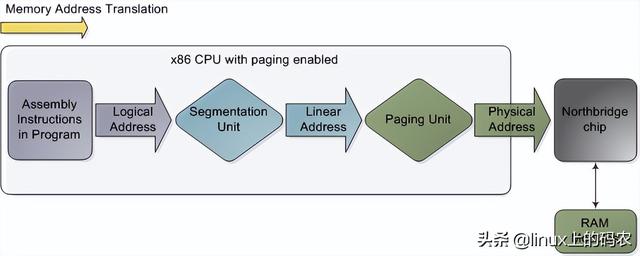
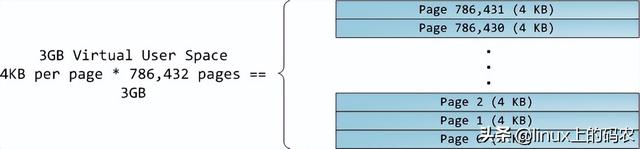
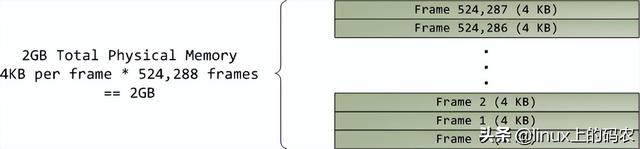
本文分析了一台现代实用的个人电脑CPU(Intel Core 2 Duo 3.0GHz)以及各种子系统的运行速度-延迟和数据吞吐量。粗略估算PC各组件的相对运行速度,希望能给大家留下更直观的印象。本文中的数据来自实际应用,而不是理论最大值。时间单位是纳秒(ns,十亿分之一秒),毫秒,(ms,和秒(s)。兆字节为兆字节(MB)和千兆字节(GB)。让我们先从CPU从内存开始,下图为北桥部分:
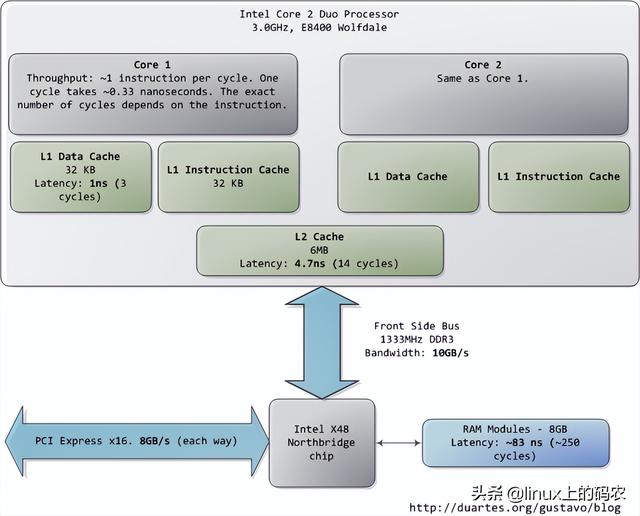
第一个令人惊叹的事实是:CPU快得离谱。在Core 2 3.0GHz大多数简单指令的执行只需要一个时钟周期,即1/3纳秒。即使是真空中传播的光,在此期间也只能走10厘米(约4英寸)。把上述事实记在心里是好的。当你想优化程序时,你会想到今天执行指令的费用。CPU多么微不足道。
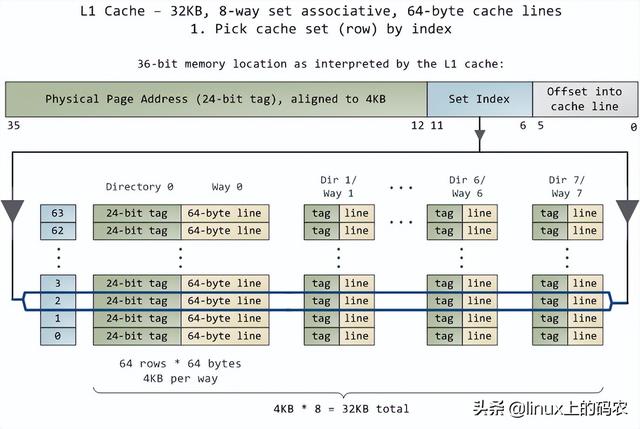
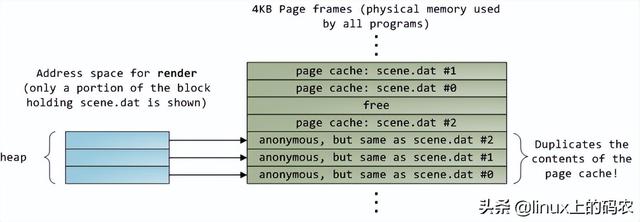
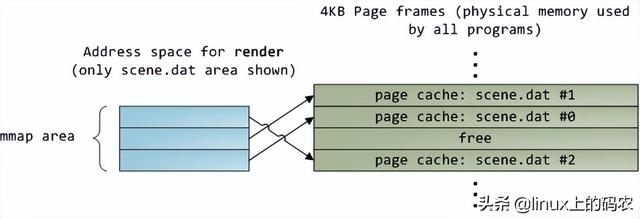
当CPU运转后,它会通过L1 cache和L2 cache读写访问系统中的主存。cache使用静态存储器(SRAM)。与系统主存中使用的动态存储器相比(DRAM),cache读写速度快得多,成本也高得多。cache一般放在里面CPU芯片内部,加上昂贵的高速存储器,给它CPU延迟很低。优化指令层次(instruction-level optimization),其效果与优化后代码的大小密切相关。由于使用了高速缓存技术(caching),那些可以整体放入L1/L2 cache在运行过程中,代码和那些需要不断调出/调出的代码(marshall into/out of)cache代码在性能上会有非常明显的差异。
正常情况下,当CPU在操作内存区域时,要么保存了信息L1/L2 cache,要么需要从系统主存中转移cache,再处理。如果是后一种情况,我们会遇到第一个瓶颈,大约250小时的延迟。如果在此期间CPU没有别的事要做,往往处于停机状态(stall)。为了给你一个直观的印象,我们把它放在一边CPU一个时钟周期被视为一秒钟。那么,从L1 cache读信息就像拿起桌子上的草稿纸(3秒);从L2 cache读取信息是从书架上拿出一本书(14秒);从主存中读取信息相当于下楼买零食(4分钟)。
与具体应用等诸多因素有关,主存操作的准确延迟是不固定的。例如,它依赖于列选通延迟(CAS)它还依赖于内存条的型号CPU成功率取的成功率。根据当前执行的代码,可以猜测主存的哪些部分即将使用,以便提前将这些信息输入cache。
看看L1/L2 cache对比主存的性能,会发现配置更大cache或者写作可以更好地利用cache应用程序将显著提高系统的性能。
人们通常把CPU内存之间的瓶颈叫冯·诺依曼瓶颈(von Neumann bottleneck)。今天系统的前端总线带宽约为10GB/s,看上去很满意。在这个速度下,你可以在1秒内从内存中读取8GB10纳秒内读取100字的信息 节。遗憾的是,这个吞吐量只是理论最大值(图中其他数据为实际值),而且是根本不可能达到的,因为主存控制电路会引入延迟。在进行内存访问时,会遇到很多零 等待周期分散。例如,电平协议要求在选择一行、一列和获取可靠数据之前,有一定的信号稳定时间。为了防止自然,主存储使用电容器存储信息 放电造成的信息丢失需要定期刷新其存储的内容,这也带来了额外的等待时间。一些连续的内存访问可能更有效,但仍有延迟。而那些随机 内存访问需要更多的时间。因此,延迟是不可避免的。
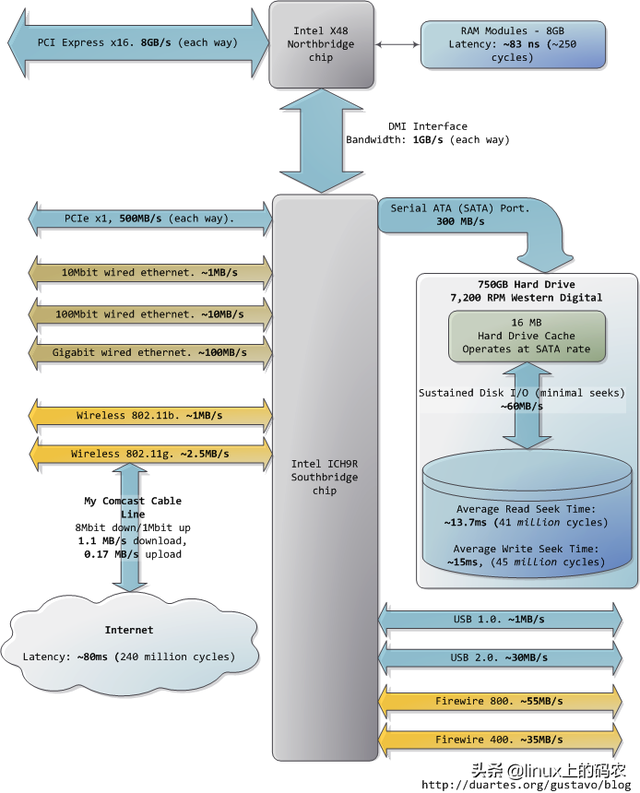
许多其他总线(如:PCI-E, USB)和外围设备:
?
令人沮丧的是,南桥管理了一些反应迟钝的设备,如硬盘。即使是缓慢的系统主存,与硬盘相比可以说速度如飞。继续把办公室作为比喻,等待硬盘找到相当于离开办公楼,开始长达一年零三个月环球之旅。这就解释了为什么计算机的大部分工作都是由磁盘控制的I/O,以及为什么数据库的性能在内存缓冲区耗尽后突然下降。它还解释了为什么它足够了RAM(用于缓冲)和高速磁盘驱动对系统的整体性能如此重要。
虽然磁盘的"连续";访问速度确实可以在实际使用中实现,但这并不是故事的全部。真正令人头疼的瓶颈是通道操作,即将读写磁头移动到磁盘表面的正确磁道,然后等待磁盘旋转到正确的位置,以阅读指定风扇区域的信息。RPM用于指示磁盘的旋转速度:RPM在寻道上耽误的时间越大,所以越高RPM磁盘越快。
当 由于节省了寻道时间,磁盘驱动器在阅读一个大的连续存储文件时会达到更高的连续读取速度。文件系统的碎片整理器用于重组连续数据块中的文件信息 数据吞吐量通过尽可能减少搜索来提高。然而,说到计算机实际使用的感觉,磁盘的连续访问速度并不那么重要。相反,应注意驱动器可以在单位时间内完成 寻道与随机I/O操作次数。固态硬盘可以成为一个很好的选择。
硬盘的cache也有助于提高性能。虽然16MB的cache只能覆盖整个磁盘容量的0.002%,不要看cache只有这么大一点,很明显。它可以将一组分散的写入操作合成一个,即使磁盘能够控制写入操作的顺序,从而减少通道的数量。同样,为了提高效率,还可以重组一系列读取操作,以及操作系统和驱动固件(firmware)参与这种优化。
最后,网络和其他总线的实际数据吞吐量也列在图中。火线(fireware)仅供参考,Intel X48芯片组不直接支持火线。我们可以把Internet它被视为计算机之间的总线。访问速度快的网站(比如google.com),延迟约45毫秒,相当于硬盘驱动器的延迟。事实上,尽管硬盘比内存慢5个数量级,但它的速度和速度Internet在同一数量级上。目前,一般家用网络的带宽仍落后于硬盘连续读取速度,但";网络是计算机;";这句话可谓名符实际。如果将来Internet比硬盘快,会是什么场景?
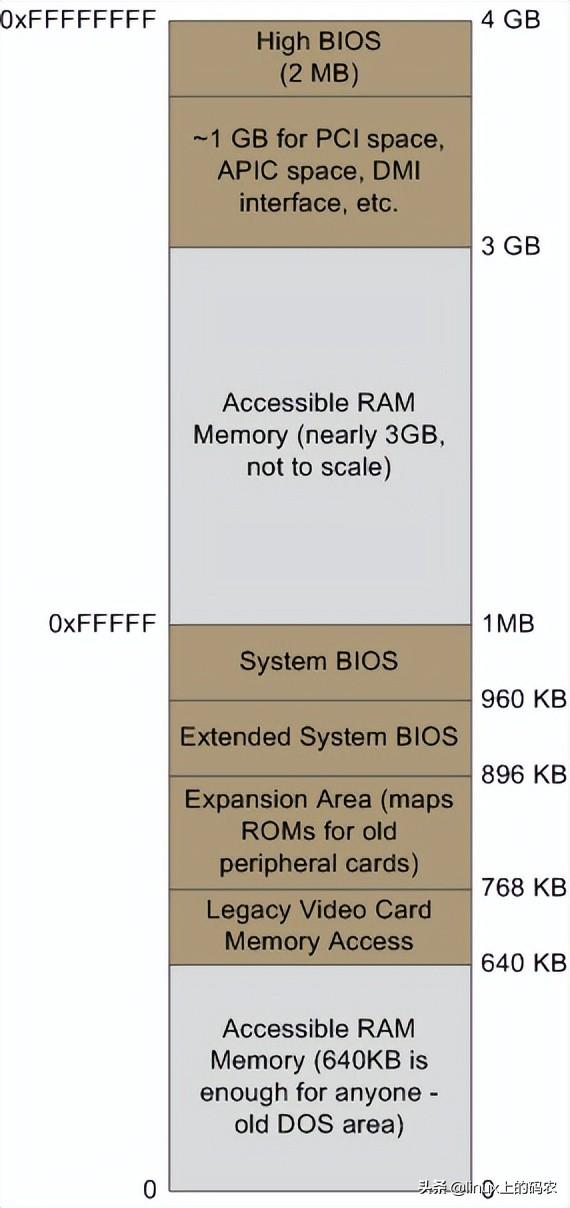
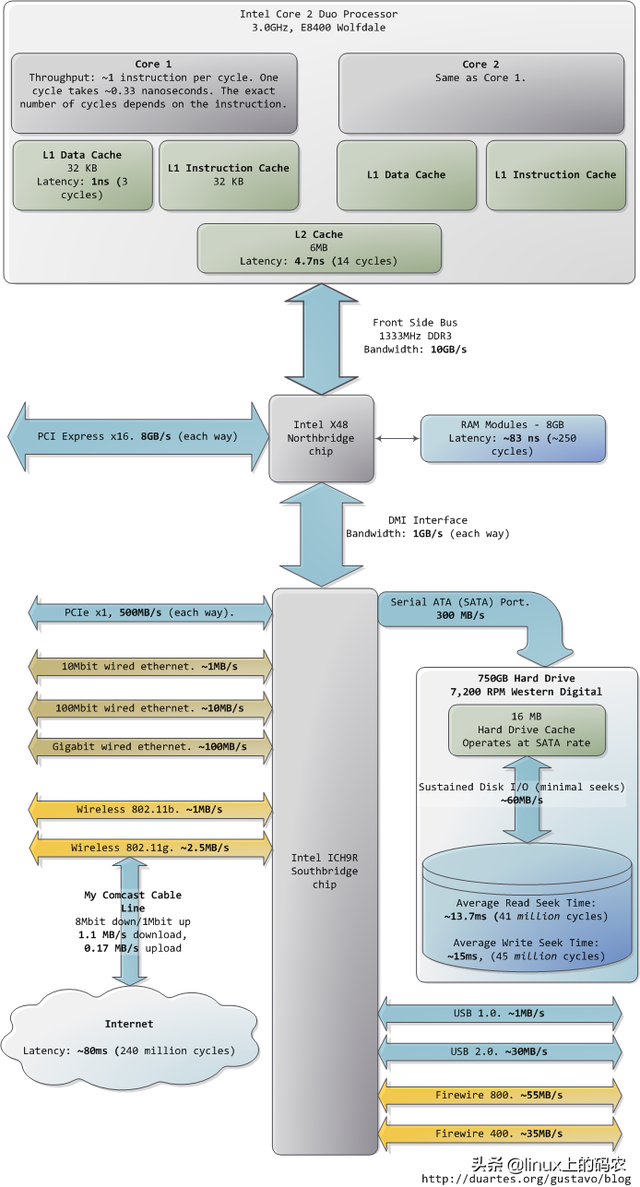
我希望这些照片能对你有所帮助。当这些数字呈现在我面前时,它们真的很迷人,让我看到了计算机技术的发展。前面分开的两张图片只是为了方便叙述。我还贴了包括南北桥在内的整张图片供您参考。
?
更多linux内核视频教程文档免费收到后台私信【内核】自行获取.
Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂
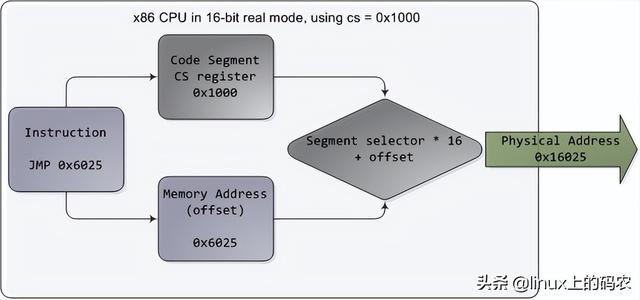
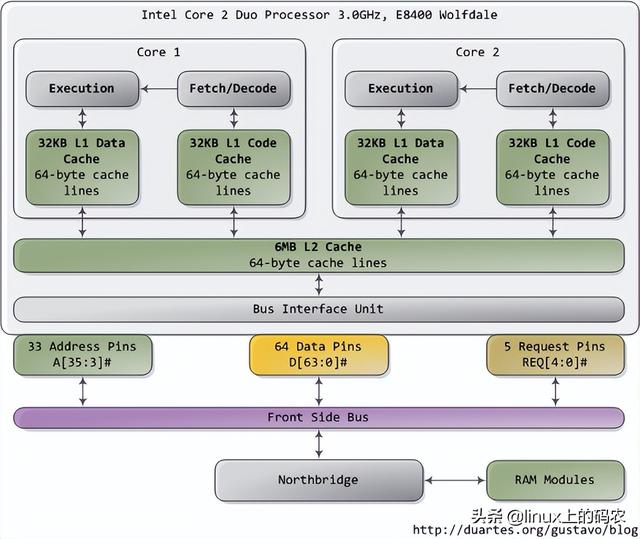
当你试图理解一个复杂的系统时,如果能揭开表面的抽象,专注于最低层次的概念,往往会有很大的收获。在这种精神的指导下,让我们来看看内存和I/O端口操作是最简单、最基本的概念,即CPU与总线的接口。在这种精神的指导下,让我们来看看内存和I/O端口操作是最简单、最基本的概念,即CPU与总线的接口。细节是许多上层概念的基础,如线程同步。当然,既然我是程序员,我暂时忽略了只有电子工程师才会关注的东西。下图是我们的老朋友,Core 2:
?
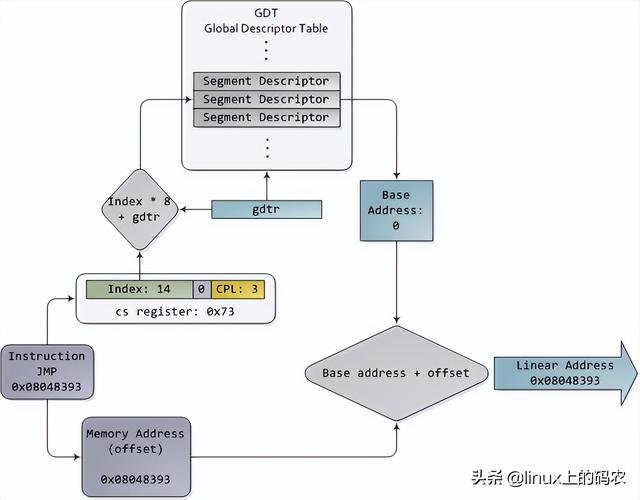
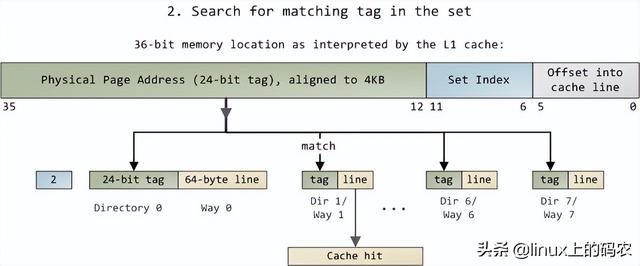
Core 2 处理器有775个管脚,其中约一半仅用于供电而不参与数据传输。当你根据功能对这些管脚进行分类时,你会发现处理器的物理界面惊人而简单。本图显示了参与内存和I/O重要的管脚:地址线、数据线、请求线。这些操作都发生在前端总线下文结构(the context of a transaction)中。实施前端总线事务包括仲裁、请求、侦听、响应、数据操作五个阶段。在执行事务的过程中,前端总线的各个部件起着不同的作用。这些部件被称为agent。通常,agent就是全部的处理器外加北桥。
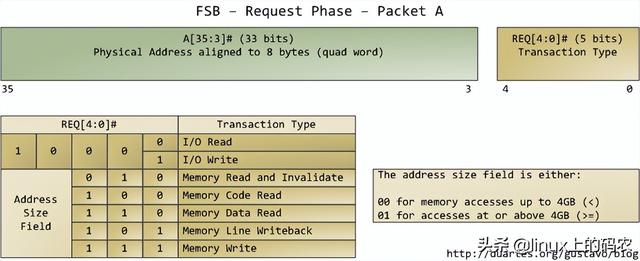
本文仅分析请求阶段。在这个阶段,发出请求agent它通常是一个输出两个数据包的处理器。下图列出了第一个数据包中最重要的位置,通过处理器的地址线和请求线输出:
?
地址线输出指定了物理内存的起始地址。我们有33条地址线,他们指定了数据包的第35至第3位,第2至第0位为0。因此,这33条地址线实际上构成了一个36位、8字节对齐的地址,只覆盖了64条GB物理内存。从奔腾开始Pro就开始了。请求线指定了事务类型。事务类型为I/O请求时,地址线指出I/O而不是内存地址。当第一个数据包被发送时,第二个数据包也被管脚发送到下一个总线时钟周期:
?
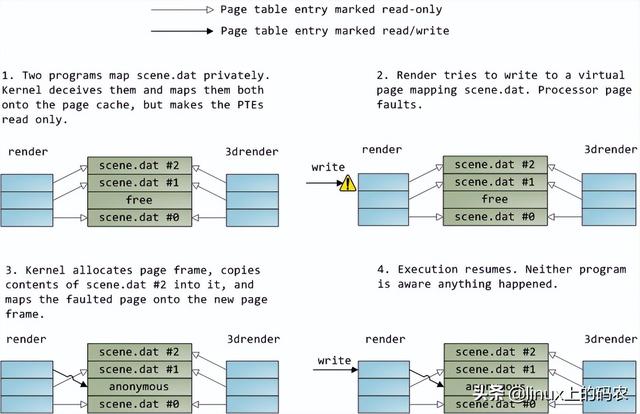
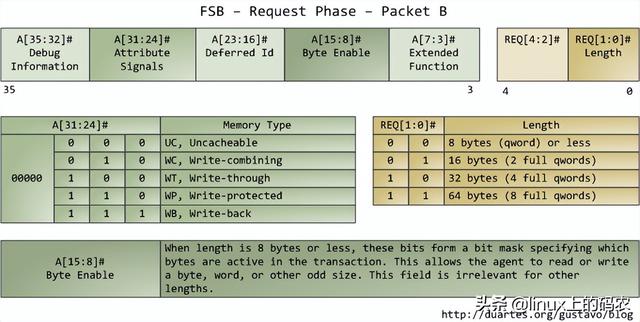
属性信号(attribute signal A[31是,它反映了Intel处理器支持的五种内存缓冲功能。将这些信息发布到前端总线后,发出请求agent其他处理器可以知道如何根据当前事务处理自己cache,让内存控制器(即北桥)知道如何处理。一块指定内存区域的缓存类型由处理器通过查询页表(page table)决定页表的原因OS内核维护。
典型的情况是,核心将所有内存视为"回写"类型(write-back),从而获得最佳性能。在回写模式下,内存的最小访问单元是缓存线(cache line),在Core 2中是64字节。当程序想读取内存中的字节时,处理器会从L1/L2 cache读取整个字节缓存线的内容。当程序写入内存时,处理器只是修改cache主存中的信息不会更新。之后,当主存真的需要更新时,处理器会将修改后的缓存线放在总线上,一次性写入内存。因此,大多数请求事务的数据长度字段为11(REQ[1:0]),对应644 字节。下图展示了当cache内存读取访问的过程:
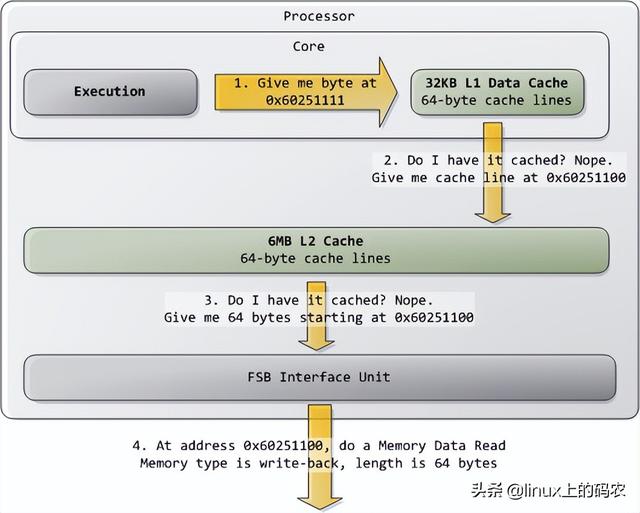
?
在Intel在计算机上,一些物理内存范围被映射到设备地址,而不是实际的RAM硬盘和网卡等存储地址。这使得驱动程序与设备通信方便,就像读写内存一样。这种内存映射区域将标记在页表中不可缓存的(uncacheable)。无缓存内存区域的访问操作将由总线完好无损地执行,其操作与应用程序或驱动程序发出的要求完全一致。因此,程序可以准确地控制单个字节、单词或其他长度的读写信息。这些都是通过在第二个数据包中设置字节来掩码的(byte enable mask A【15:8】完成。
这些基本知识也包含了许多相关内容。比如:
1、 如果应用程序想要尽可能高的运行速度,就应该在同一缓存线中组织会一起访问的数据。这条缓存线一旦载入,读取操作就会加快很多,不再需要额外的内存访问。
2、 对于回写内存访问,任何作用于缓存线的内存操作都必须是原子(atomic)。这种能力是由处理器制成的L1 cache所有数据同时读写,其他处理器或线程不会中断。特别是,只要不跨越缓存线的边界,32位和64位的内存操作就是原子操作。
3、 所有的前端总线agent所共享的。这些agent在开始事务之前,必须仲裁总线使用权。而且,每一个agent为了维持总线上所有的事务都需要侦听,cache的一致性。因此,部署更多的多核处理器Intel计算机,总线竞争问题会越来越多 严重