文/ 阿里 淘系 F(x)Team - 旭伦
通过机器学习可以自动修复bug? 对许多学生来说,这可能是一个奇妙的话题。 不管靠不靠谱,我们大家都能学会。
这个问题很难说,也很简单。我们把有bug修复后的代码片断和代码片断制成数据集,使用类似的机器翻译技术进行训练。然后我们用训练好的模型来预测如何修复新代码。 这个想法和数据集都来自论文《An Empirical Study on Learning Bug-Fixing Patches in the Wild via Neural Machine Translation》
代码自动修复的主题非常简单,一段是bug另一段是修复后的代码。
我们看图片的主要过程:
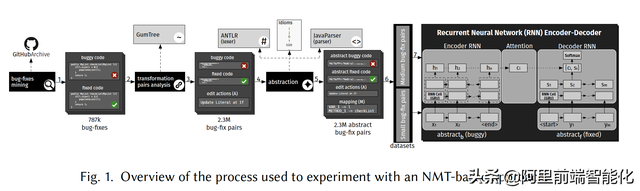
为了更好地适应代码,作者抽象了代码:

让我们来看一个数据集中的例子:
有bug代码如下:
public java.lang.String METHOD_1 ( ){ return new TYPE_1 ( STRING_1 ) . format ( VAR_1[ ( ( VAR_1 . length ) - 1 ) ]. getTime ( ) ) ; }
修复后是这样的:
public java.lang.String METHOD_1 ( ){ return new TYPE_1 ( STRING_1 ) . format ( VAR_1[ ( ( type ) - 1 ) ]. getTime ( ) ) ; }教你手把手用CodeBERT自动修复bug
人工智能服务于软件工程AI4SE方面,微软一直处于领先地位。让我们手拉手学习如何使用微软。CodeBERT自动修复模型bug.
第一步:安装transformers框架,因为CodeBERT 基于此框架:
pip install transformers --user
第二步:安装PyTorch或者Tensorflow作为Transformers如果驱动能够完成后端,简单地安装最新的:
pip install torch torchvision torchtext torchaudio --user
第三步,下载微软数据集
git clone https://github.com/microsoft/CodeXGLUE
已下载数据集CodeXGLUE/Code-Code/code-refinement/data/ 中了,分为small和medium两个数据集。
我们先拿small数据集练习:
cd codeexport pretrained_model=microsoft/codebert-baseexport output_dir=./outputpython run.py \\--do_train \\--do_eval \\--model_type roberta \\--model_name_or_path $pretrained_model \\--config_name roberta-base \\--tokenizer_name roberta-base \\--train_filename ../data/small/train.buggy-fixed.buggy,../data/small/train.buggy-fixed.fixed \\--dev_filename ../data/small/valid.buggy-fixed.buggy,../data/small/valid.buggy-fixed.fixed \\--output_dir $output_dir \\--max_source_length 256 \\--max_target_length 256 \\--beam_size 5 \\--train_batch_size 16 \\--eval_batch_size 16 \\--learning_rate 5e-5 \\--train_steps 100000 \\--eval_steps 5000
这取决于你机器的计算能力,我用一台NVIDIA 3090GPU训练大约需要一个晚上。存储在效果最好的模型中的最佳模型output_dir/checkpoint-best-bleu/pytorch_model.bin中。
然后我们可以用测试集来测试我们的训练结果:
python run.py \\ --do_test \\--model_type roberta \\--model_name_or_path roberta-base \\--config_name roberta-base \\--tokenizer_name roberta-base \\--load_model_path $output_dir/checkpoint-best-bleu/pytorch_model.bin \\--dev_filename ../data/small/valid.buggy-fixed.buggy,../data/small/valid.buggy-fixed.fixed \\--test_filename ../data/small/test.buggy-fixed.buggy,../data/small/test.buggy-fixed.fixed \\--output_dir $output_dir \\--max_source_length 256 \\--max_target_length 256 \\--beam_size 5 \\--eval_batch_size 16
在我的机器上,经过半小时的推理计算,输出如下:
10/26/2021 11:51:57 - INFO - __main__ - Test file: ../data/small/test.buggy-fixed.buggy,../data/small/test.buggy-fixed.fixed100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 365/365[30:40<00:00, 5.04s/it]10/26/2021 12:22:39 - INFO - __main__ - bleu-4 = 79.26 10/26/2021 12:22:39 - INFO - __main__ - xMatch = 16.3325 10/26/2021 12:22:39 - INFO - __main__ - ********************
我们生成的代码质量如何评价?我们可以比较我们生成的output/test_1.output和output/test_1.gold进行比较,可使用以下内容evaluator.py脚本:
python evaluator/evaluator.py -ref ./code/output/test_1.gold -pre ./code/output/test_1.output
输出结果如下:
BLEU: 79.26 ; Acc: 16.33
前者是描述NLP生成质量的BLEU指标,后者是准确性。
这个指标水平如何?我们可以比较基线:
Method | BLEU | Acc (100%) | CodeBLEU |
Naive copy | 78.06 | 0.0 | - |
LSTM | 76.76 | 10.0 | - |
Transformer | 77.21 | 14.7 | 73.31 |
CodeBERT | 77.42 | 16.4 | 75.58 |
虽然精度看起来不高,但是CodeBERT比原论文用的更多RNN技术提高了60%。
我们通过diff直观感受生成与原始的区别:
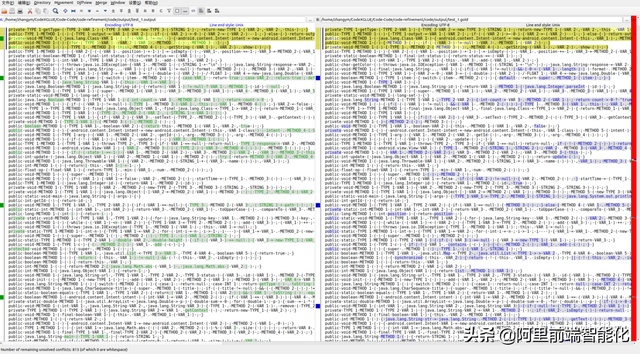
随着数据的增加,我们可以自动帮助我们修复,而不需要脑细胞bug,这简直就是睡后收入。
自动发现bug若感觉自动解决bug这件事离实用还很远,我们可以先发现bug。
自动发现bug
若感觉自动解决bug这件事离实用还很远,我们可以先发现bug。 不要低估自动发现bug这个相对较弱的命题大大提高了它的适用性和准确性。
是否有bug数据集特别简单,只要用一个字段来标记是否有bug就可以了。以下是数据集格式jsonl格式存储: